Finding the Perfect Flight: Solving a 5,000-Option Search Problem at Otto
Searching SF → NYC isn’t scrolling through 250 flights - it’s navigating 5,000+ possibilities! Every route, cabin, fare rule, and baggage policy spawns a new branch in the search tree, and that’s before loyalty status, seat availability, or the real question: do you at least get snacks?


Every existing system silently hands the problem back to the user: open 20 tabs, build a spreadsheet, hope you didn't miss the option on page 7. At Otto we believe this isn't a ranking problem, but rather an agentic search problem. And I'd like to share our journey of taking on this complexity. The technical challenges turned out to be quite interesting, more than we anticipated.
What's a "Flight Option"?
A flight option isn't just a flight. It's the combination of:
- Flight route: Direct or connections (SFO→JFK direct, or SFO→ORD→JFK)
- Cabin class: Economy, Premium Economy, First, plus seat upgrades
- Fare type: Basic Economy, Main Cabin, Flexible, each with different policies
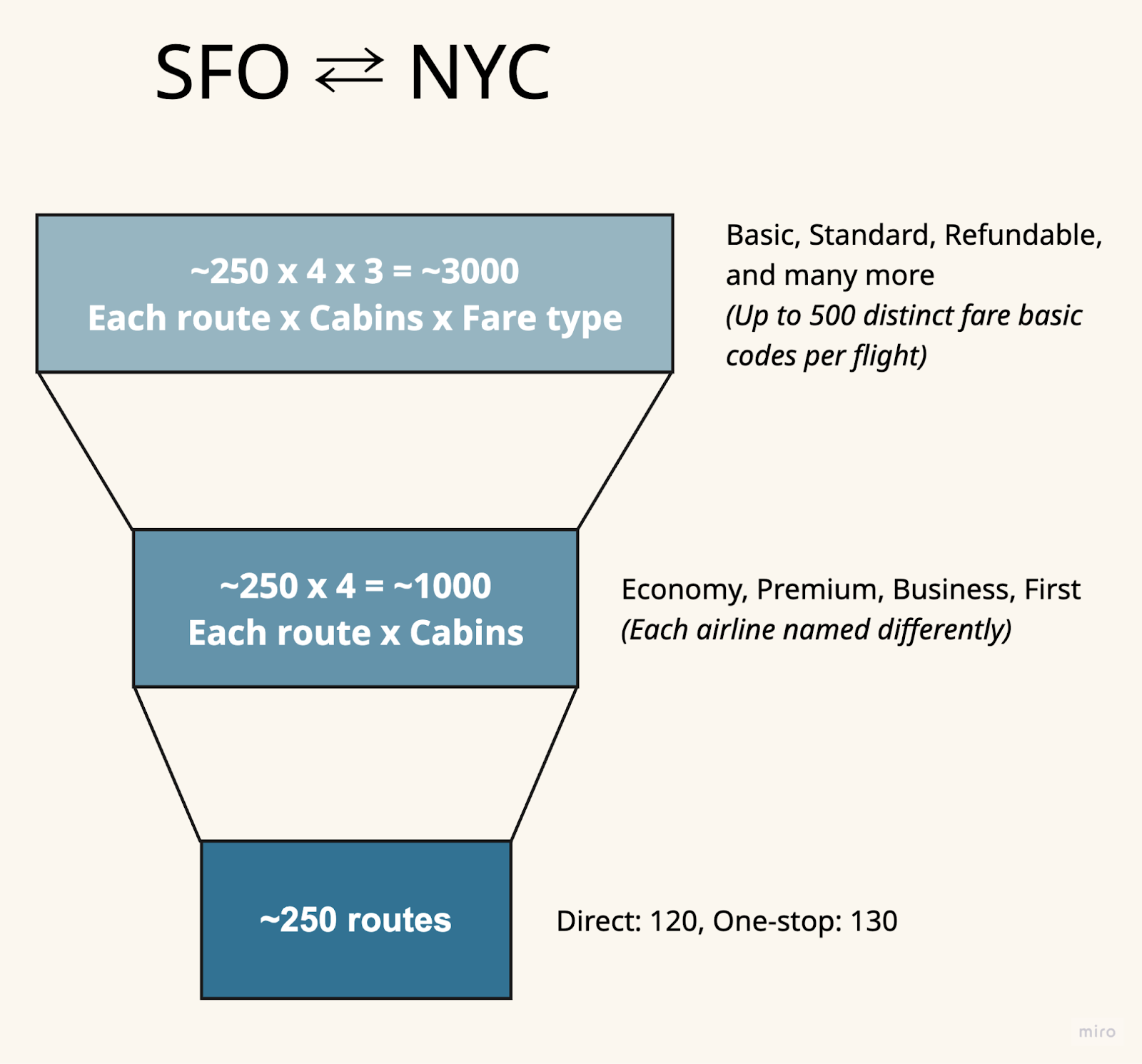
A typical domestic search like San Francisco to New York returns ~250 flight routes (accounting for all NYC airports and 1-stop options). Each route has 3-5 cabin classes, and each cabin would have 3-4 fare types (fare basic code could create up to 500 different fare options per flight).
250 routes × 4 cabins × 3 fares = 3,000 flight options minimum. Add mixed-cabin bookings, alternative airports, and partner airlines, and you're above 5,000 options.
These are all potentially valid answers depending on what the user cares about. You can't know which one is perfect without understanding what the user actually wants - and that's the core challenge.
Why You Can't Just Filter Down
The naive solution seems obvious: Convert user preferences into search filters.
- User says "I prefer United" → Filter to United only
- User says "under $400" → Filter by price
- User says "direct flights" → Remove connections
Pass the remaining 50 options to the model, have it pick the best one. Done, right?
This approach fails because preferences aren't hard constraints - they're signals for reasoning.
Example 1: The Loyalty Trap
User input: "I fly United for status, prefer direct flights, need to arrive by 6pm for dinner plans"
If you filter to "United + direct flights only," you get:
- United direct, Economy Plus: $450, arrives 5:30pm ❌ (sold out of cheaper seats)
- United direct, Basic Economy: $280, arrives 5:45pm ✅ (but no carry-on, no seat selection)
But the full search space includes:
- Delta direct, Main Cabin: $310, arrives 5:30pm, includes carry-on and seat selection
- JetBlue direct, Blue: $290, arrives 5:15pm, includes carry-on, extra legroom, free WiFi
If Otto only sees the filtered United options, it can't reason about whether saving $170 is worth switching airlines. The user said "prefer United," not "United only." Maybe they'd gladly fly Delta if they understood the trade-off.
The agent needs to see the alternatives to explain why breaking a preference makes sense.
Example 2: The False Economy Problem
User input: "Cheapest option, need to arrive by 6pm"
If you filter by "lowest price," the top result is:
- Spirit one-stop via Las Vegas: $180, arrives 6:15pm ❌ (too late)
- Frontier one-stop via Denver: $195, arrives 5:45pm ✅
But a slightly more expensive option is:
- Alaska direct: $265, arrives 5:30pm, includes carry-on and checked bag
For a business traveler, the Frontier flight is a false economy: add carry-on fee ($65), checked bag ($50), and you're at $310 with schedule risk on a budget airline connection. But if you filter purely by price, the agent never sees the context to apply this "pro tip."
The key insight: Preferences tell you what to optimize for, not what to exclude. The agent needs search space to explore trade-offs.
The Three-Way Reasoning Challenge
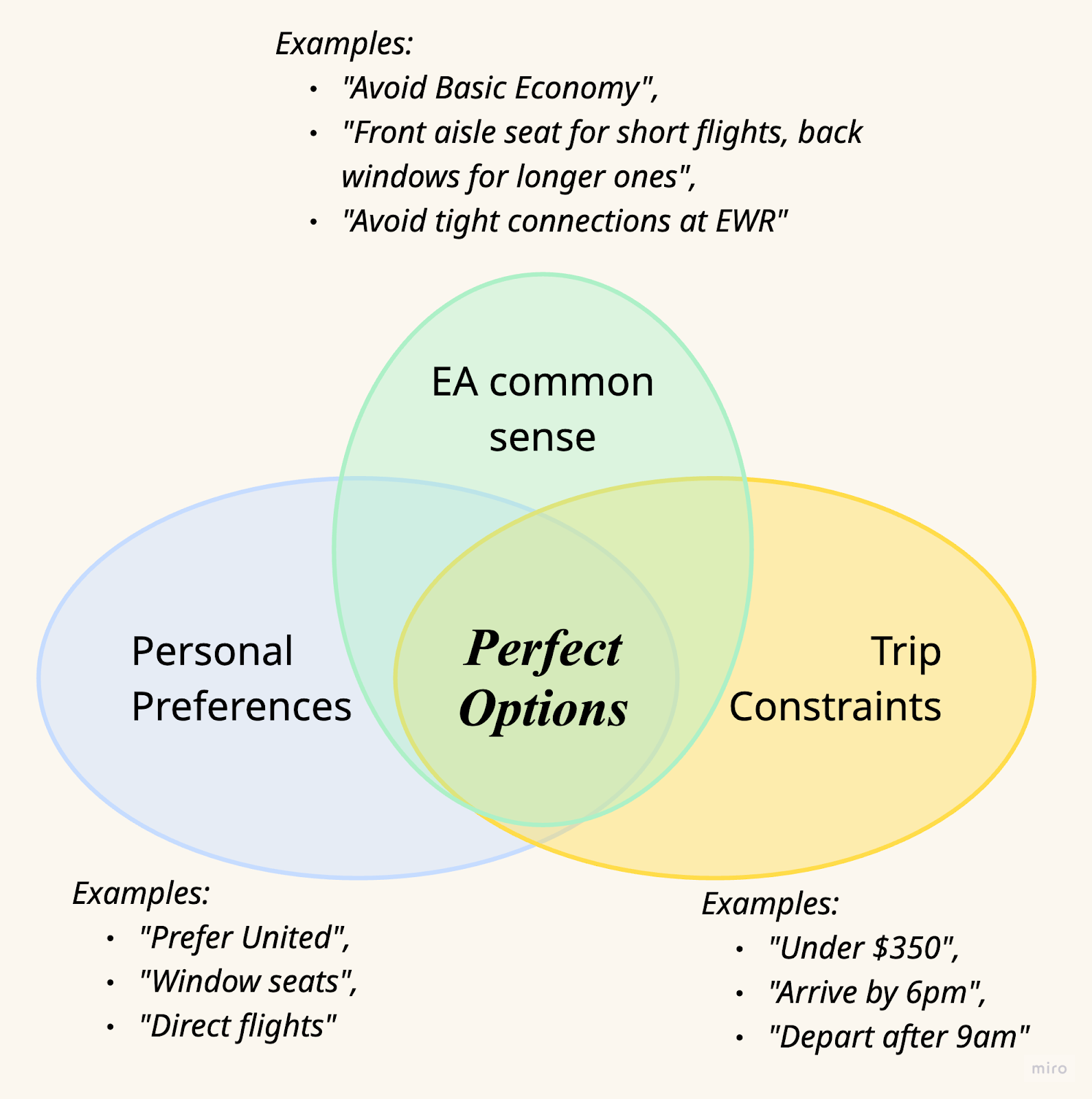
So we can't pre-filter aggressively. That means Otto needs to explore a large search space and rank options by reasoning through three competing signals:
- Personal preferences: "I fly United for status"
- Trip constraints: "Must arrive by 6pm, under $350"
- EA common sense: "Don't book Basic Economy if you need a carry-on"
The hard part? These three frequently contradict each other, and there's no universal priority order.
Let's walk through a real scenario to see why this is technically challenging.
Scenario: The Friday Evening Arrival
User Input:
- Preference: "I fly United for status, prefer direct flights"
- Constraint: "Need to arrive Friday by 6pm for dinner, under $350"
- Context: Business traveler, United Silver status, traveling from San Francisco
Search Returns (simplified to 8 options):
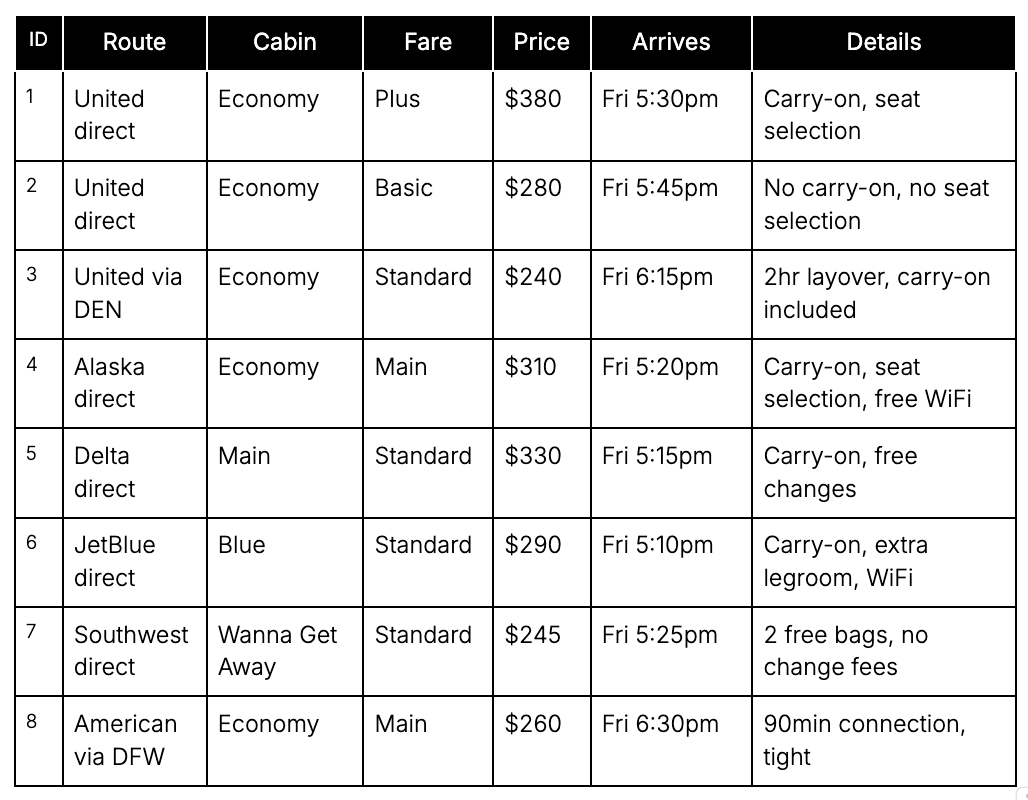
What should Otto recommend?
At first glance:
- Option 2 (United Basic $280) is cheapest within budget and meets the arrival constraint
- But it's the wrong answer
The model needs to reason through multiple conflicts:
Conflict 1: Preference vs EA common sense
Option 2 satisfies "prefer United" but violates "don't book Basic Economy for business travelers."
Why? For a business trip:
- No changes = If dinner plans shift, you've lost $280
- No seat selection = Risk middle seat on a 5+ hour flight
- No carry-on = Must check bag ($35 fee) or travel with only a personal item (unlikely for work trip)
Real cost: $315+ with high risk
Option 4 (Alaska $310) breaks "prefer United" but:
- Includes carry-on and seat selection
- Alaska partners with American, so you still earn some miles
- Earlier arrival (5:20pm) gives 40min buffer
- Free WiFi (work on the flight)
Real cost: $310 with flexibility and comfort
The reasoning needs to be comparative and fact-based:
Bad reasoning: "Option 2 might have fees"
Good reasoning: "Option 2 (United Basic $280) appears cheapest, but for a business trip you'll need a carry-on ($35 fee) bringing the real cost to $315. You'll also be assigned a random seat - likely a middle. Option 4 (Alaska $310) includes carry-on and seat selection, arrives earlier (5:20pm vs 5:45pm), and includes free WiFi. The $5 difference buys you a much better experience, and you'll still earn American miles through Alaska's partnership."
Conflict 2: Constraint vs EA common sense
Option 7 (Southwest $245) is $65 cheaper than Option 4 and well under budget.
However, it:
- Arrives 5:25pm (35min buffer is tight for dinner at 6pm)
- Southwest doesn't participate in traditional alliances (no miles for United status)
- Southwest uses open seating (no advance seat selection)
But it also:
- Includes 2 free checked bags
- No change fees (full flexibility)
- Direct flight, good reliability
The model needs to weigh: Is United status worth $65 on this trip?
Good reasoning: "Option 7 (Southwest $245) saves $65 vs Option 4 and offers great value - 2 free bags, no change fees, solid on-time performance. The 5:25pm arrival gives you 35 minutes to get to dinner, which is workable if dinner is near the airport or flexible. However, Southwest doesn't credit to United, so you won't make progress toward Premier Gold. If you're prioritizing status this year, Option 4 is worth the premium. If flexibility and cost matter most for this trip, Option 7 is the smarter choice."
Notice: The model doesn't make the decision. It surfaces the trade-off with facts so the user can decide.
Conflict 3: When Everything Contradicts
Now imagine the user adds: "Actually, I need a window seat for this flight - I get motion sick in the middle seats."
Now the constraints multiply:
- Option 2 (United Basic): Can't select window ❌
- Option 4 (Alaska): Can select window ✅ but breaks "United only"
- Option 7 (Southwest): Open seating, must board early to get window (unpredictable) ❌
What's the priority order?
This is where it gets really hard, because the answer depends on context the user might not have explicitly stated:
- If motion sickness is severe → Guaranteed window seat trumps everything, eliminate Options 2 & 7
- If the user books flights monthly → They understand their preferences are flexible
- If the user has never mentioned motion sickness before → This is new context, weight heavily
Technical question: How do you teach the model to infer priority?
We've experimented with three approaches:
Approach 1: Ask the user and store to the user’s preference
Pros: Clear, consistent
Cons: Too many questions especially during first couple of trips
Approach 2: Let the Model Reason Give the model user history and let it infer:
- "You've mentioned comfort preferences in 8 of your last 10 bookings → this seems important to you"
- "You've never paid more than $400 on this route → $380 may be stretching your typical budget"
Pros: Contextual, adapts per trip
Cons: Requires rich user data, longer reasoning latency
Approach 3: Surface Multiple Options When conflicts are irreconcilable, show 2-3 options with clear trade-off explanations:
- Option A: "Best for United status"
- Option B: "Best balance of cost and comfort"
- Option C: "Most flexible, cheapest"
Pros: User makes the final call, Otto learn from the user’s choice
Cons: Defeats the "Otto picks for you" promise
We currently use a hybrid: Model reasons through priority based on trip context, but surface alternatives when trade-offs are close.
The Context Window Problem
Okay, so the model needs to explore a large search space and do deep comparative reasoning. But here's the constraint that makes this really hard:
You can't fit 5,000 flight options into the context.
The math:
A detailed flight option with all relevant data: ~150-200 tokens
- Route details (origin, destination, layover airports, times): 40 tokens
- Pricing (base fare, taxes, fees): 20 tokens
- Cabin details (seat dimensions, amenities, upgrade availability): 30 tokens
- Fare rules (baggage, changes, cancellation policy): 40 tokens
- Loyalty program data (miles earned, elite benefits, marketing vs operation carrier): 20 tokens
175 tokens × 5,000 options = 875,000 tokens
This by itself is approaching the context window limit of most large language models. And that's before system prompts, user context, or output space.
Even if you could fit it, should you?
Probably not. Passing 5,000 detailed options to a model is like asking someone to find the best restaurant by reading every menu in the city. The cognitive load would degrade reasoning quality even with infinite context.
So how do you let an agent explore 5,000 options?
Our Architecture: Hierarchical Search with Agentic Refinement
We use a two-stage funnel that progressively narrows the search space while preserving the options that matter:
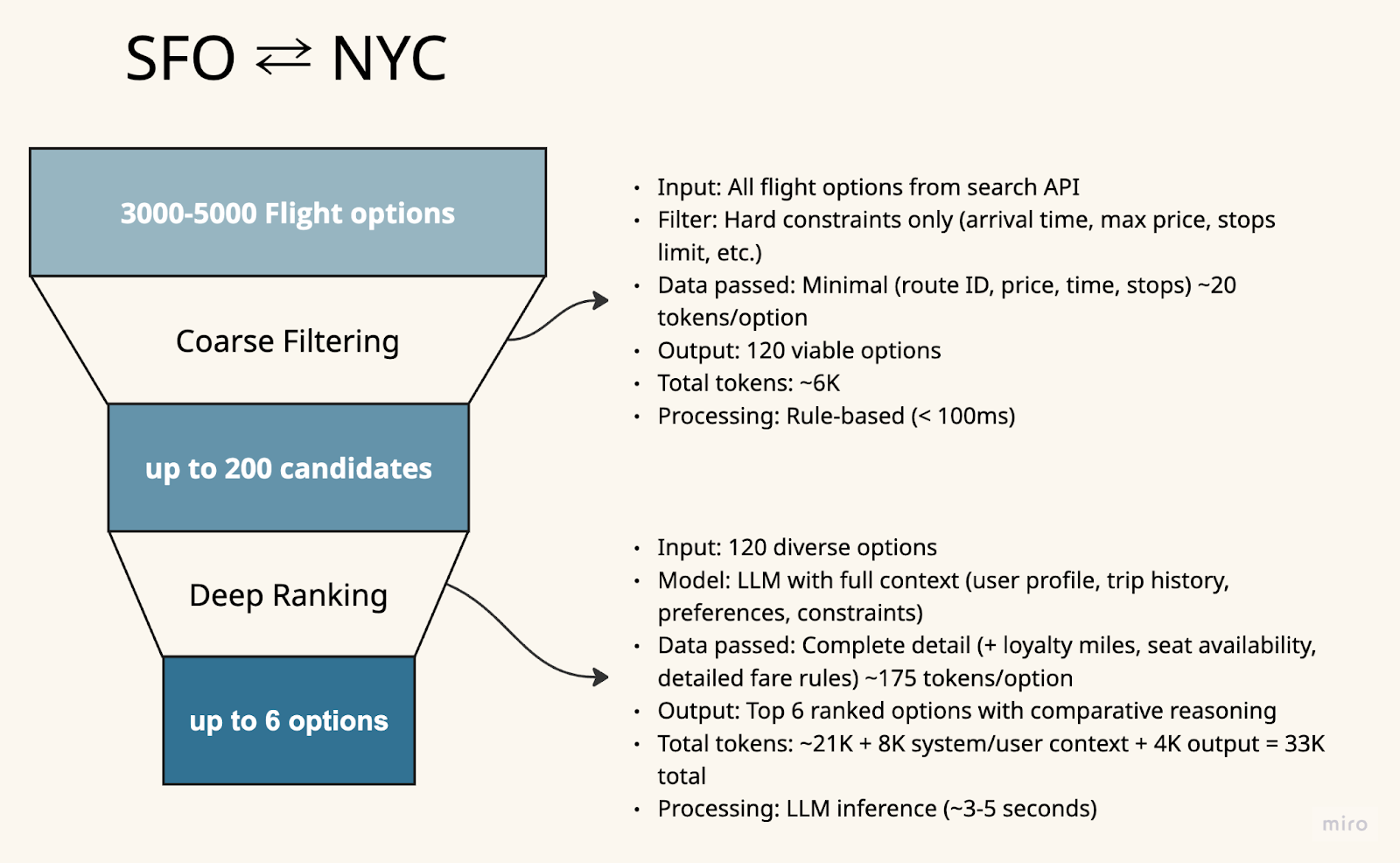
Stage 1: Coarse Filtering (5,000 → 200 options)
- Input: All flight options from search API
- Filter: Hard constraints only (arrival time, max price, stops limit, etc.)
- Data passed: Minimal (route ID, price, time, stops) ~20 tokens/option
- Output: 120 viable options
- Total tokens: ~6K
- Processing: Rule-based (< 100ms)
Stage 2: Deep Ranking (120 → Top 6 options)
- Input: 120 diverse options
- Model: LLM with full context (user profile, trip history, preferences, constraints)
- Data passed: Complete detail (+ loyalty miles, seat availability, detailed fare rules) ~175 tokens/option
- Output: Top 6 ranked options with comparative reasoning
- Total tokens: ~21K + 8K system/user context + 4K output = 33K total
- Processing: LLM inference (~3-5 seconds)
Why this works:
- Preserves search space: Stage 1 only removes impossible options (arrive after dinner, exceed budget by 3x)
- Enables deep reasoning: Stage 2 gives the model rich context on a manageable set
What Happens If You Get This Wrong?
Mistake 1: Include too much in Stage 1
We tried including fare rules in Stage 1 to "help the agent filter early."
Result: Token budget exploded to 40K for Stage 1 alone. The extra context didn't improve filtering (hard constraints don't need fare rules), and we had to reduce the search space from 5K to 2K options to fit. We missed good options.
Mistake 2: Include too little in Stage 2
We tried excluding detailed fare rules from Stage 2 to save tokens, figuring the model could reason without them.
Result: The model produced generic reasoning like "this option has more flexibility" without facts. When we A/B tested with users, the detailed version (with specific cancellation policies and change fees) was rated 40% more convincing.
The lesson: Be ruthless about Stage 1, generous with Stage 2.
Making Reasoning Convincing
At this point, the model has 80 good options and rich context. It needs to rank them and explain why.
But here's the thing: Generic explanations don't work.
We found that users trust Otto's recommendations when the reasoning is:
- Comparative (explains relative trade-offs)
- Fact-based (uses specific numbers and policies)
- Relevant (doesn't mention details the user doesn't care about)
Let's see what this means in practice:
Bad Reasoning (Vague, Non-Comparative)
Option 1:
"This is a good flight. It's affordable and arrives on time. The airline is reliable and the schedule works well."
Option 2:
"This is also a good choice with competitive pricing. It offers good value."
Option 3:
"Another solid option that meets your needs. Good balance of features."
Why this fails:
- "Good" and "affordable" are meaningless without comparison
- "Reliable airline" - compared to what?
- Doesn't explain why Option 1 is ranked above Option 2
- Each option reads like a standalone description, not a ranking
Good Reasoning (Comparative, Fact-Based, Relevant)
Option 1: Alaska direct, Economy Main, $310
"This is the best balance for your Friday trip. It departs at 9:15am, letting you work a half-day, and arrives at 5:20pm - 40 minutes before your 6pm dinner with a comfortable buffer for ground transport. The $310 price includes carry-on and seat selection. Compared to Option 2, this costs $5 more in real terms but includes free WiFi (work on the flight) and arrives 25 minutes earlier."
Option 2: United direct, Basic Economy, $280
"This option ranks second but has hidden costs. The base price is $30 cheaper than Option 1, but Basic Economy doesn't include carry-on ($35 fee) and you can't select your seat - likely ending up in a middle seat for 5+ hours. Real cost: $315, making it actually more expensive than Option 1 with a worse experience. If you're comfortable traveling with only a personal item and don't mind the middle seat risk, this saves $35 vs Option 1's true cost."
Option 3: Southwest direct, Wanna Get Away, $245
"This ranks third as the budget option. It saves $65 vs Option 1 and includes great perks - 2 free checked bags, no change fees, and Southwest's strong on-time performance. The trade-off: arrives at 5:25pm, giving you only 35 minutes to reach dinner (tight but workable if dining near the airport). More importantly, Southwest doesn't credit your United status. If you're working toward Premier Gold this year, the $65 savings means giving up 310 PQP of progress. Choose this if cost is the top priority and you're flexible on status."
Why this works:
- Comparative: Each option directly compares to others with specific dollar amounts and time differences
- Fact-based: Specific numbers (40-min buffer, $35 carry-on fee, 310 PQP, 25 minutes earlier)
- Relevant: Mentions loyalty because user stated "I fly United for status"
Optimizing for Latency
At this point, we've solved the ranking problem. The agent explores 5,000 options, reasons through trade-offs, and produces convincing explanations.
But it takes 7-9 seconds.
For context:
- Stage 1 (coarse filtering): <100ms
- Stage 2 (LLM ranking + reasoning): 6-8 seconds
Users perceive anything over 3 seconds as "slow." After 5 seconds, they start doubting the system is working.
Traditional flow:
User clicks "Search"
→ [7 seconds of blank screen]
→ Results appear with full explanations
Conversion rates crater because users think it's broken.
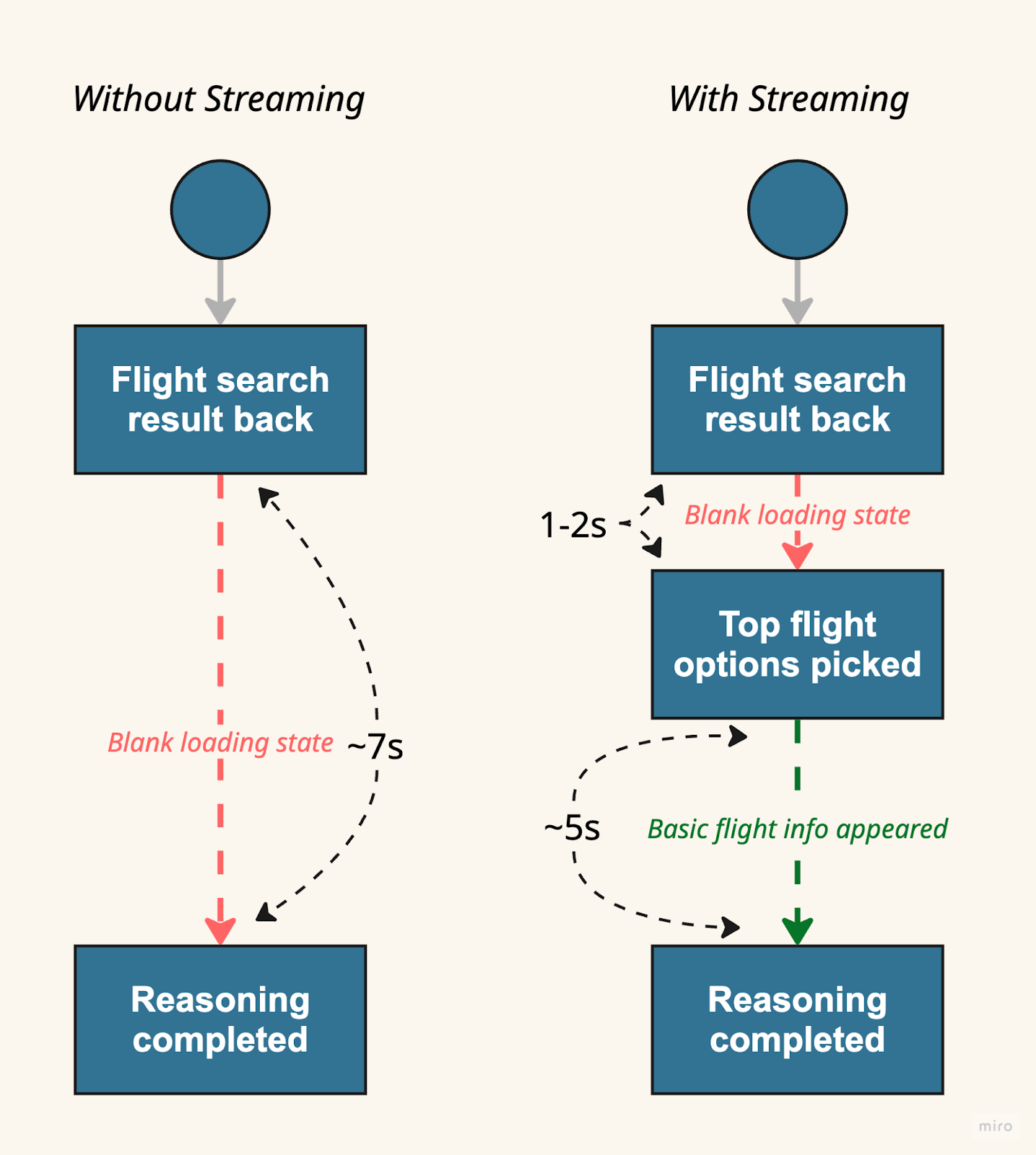
The Streaming Solution
We realized: The user doesn't need explanations immediately. They need to see something is happening.
So we restructured the model output to stream flight option IDs first, then fill in the reasoning, and improved perceived latency from 7s to 2s.
Open Questions We're Still Exploring
Building Otto has surfaced questions we don't have perfect answers to yet:
1. How do you validate that agentic exploration isn't missing good options?
We continue to do offline scoring of user conversation that’s related to flight search in order to evaluate, iterate and improve the context engineering around flight ranking process, especially if we’re giving too little (missing better options) or too much (latency too long) of a search space for Otto to explore.
2. How do you measure if reasoning is "convincing" to users?
We track:
- Click-through rate (do users book the recommended option?)
- Time-to-decision (do users keep searching after seeing results?)
- Conversation quality (# of rounds, sentiment of the follow up action)
- Explicit feedback (thumbs up/down on explanations)
But "convincing" is subjective. An expert traveler might find detailed reasoning convincing, while a casual traveler might prefer simplicity. Should we personalize reasoning depth?
3. When should the agent break a user's stated preference?
If a user says "I only fly United," should Otto show them an Alaska option that's $100 cheaper and arrives earlier? We currently do include those options, with explanation. But we've gotten feedback that this feels like Otto "ignoring" the user's preference. Where's the line between helpful and pushy?
4. How do you prevent the model from developing harmful biases?
We monitor for patterns like:
- Always preferring expensive airlines (revenue incentive)
- Preferring options that earn more miles (misaligned with user's stated "cheapest option" constraint)
- Down-ranking budget airlines due to training data bias
We audit rankings regularly, but this is an ongoing challenge.
5. Can you teach the model EA common sense without them becoming rigid rules?
Example: "Don't book Basic Economy if you need carry-on" is a good heuristic, but there are exceptions (personal item only, very short trip). How do you encode "usually avoid, but sometimes okay"? We're experimenting with showing confidence scores: "78% of travelers with carry-ons regret booking Basic Economy."
Conclusion
Flight booking is a high-cardinality problem - 5,000+ options, three competing signals, and no universal right answer. Traditional search engines pushed this complexity onto users. At Otto, we handle it with agentic AI.
The core challenges:
- Ranking requires three-way reasoning: Personal preferences, trip constraints, and EA common sense often contradict each other. The model needs to infer priority and explain trade-offs convincingly.
- Context windows force architectural decisions: You can't fit 5,000 options in a prompt. Hierarchical search with diversity sampling preserves exploration space while enabling deep reasoning.
- Latency matters more than we expected: Streaming partial results keeps users engaged while the agent completes reasoning.
We've learned that agentic AI shines in high-cardinality search problems - not just flight booking, but any domain where the perfect answer depends on implicit preferences and contextual trade-offs.
If you're building something similar, I'd love to hear:
- How do you handle multi-objective optimization when objectives conflict?
- What techniques have you found for maintaining large search spaces with limited context?
- How do you validate that your agent isn't missing good options?
Drop me a note on Linkedin or Twitter - I'm always keen to swap notes on agentic search problems.



