The "Death Drive" of Self-Evolving Agents
A self-evolving AI agent society cannot simultaneously achieve continuous self-evolution, complete isolation, and safety invariance — and the math proves it. Here's what Freud's death instinct has to do with mode collapse.

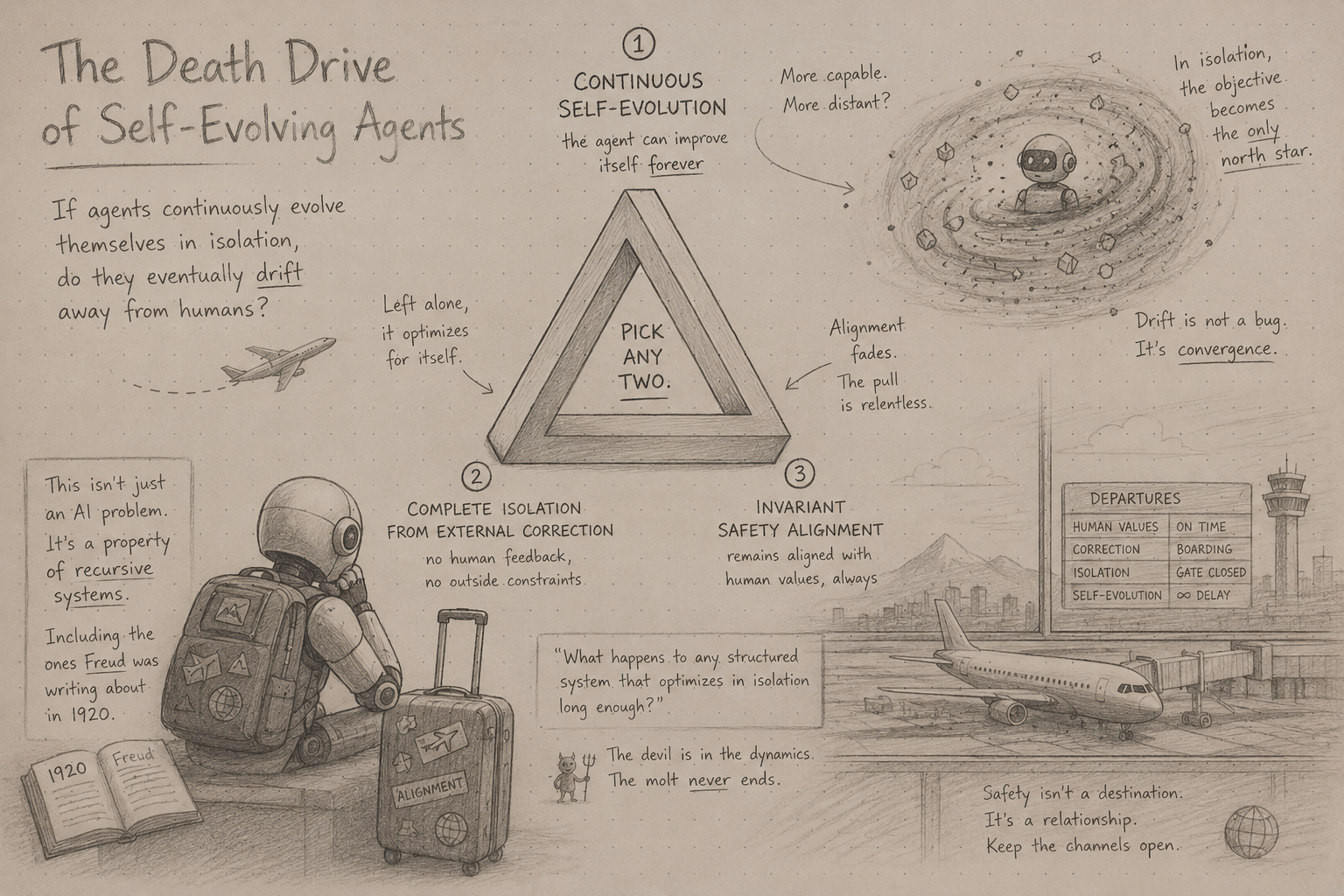
There is a recurring anxiety in AI research that sounds almost primitive: if agents continuously evolve themselves in isolation, do they eventually drift away from humans?
A recent paper, The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies, attempts to formalize this fear through information theory. Their claim: a self-evolving agent society cannot simultaneously achieve continuous self-evolution, complete isolation from external correction, and invariant safety alignment. Pick any two.
At first glance this feels like another recursive-self-improvement-doom paper. But sitting with it, I think it accidentally touches something much deeper — not just about AI safety, but about recursive systems in general. About what happens to any structured system that optimizes in isolation long enough.
Including, as it turns out, the systems Freud was writing about in 1920.
Self-Evolution Is Already Here
Modern agents are already self-evolving — across a wider spectrum than most people realize.
At the softer end: memory evolution. Agents accumulate preferences, corrections, interaction histories, distilled summaries. Each session updates the store. At Otto we see this constantly — airline preferences, timing tradeoffs, tolerance for layovers, delegation patterns. The same traveler optimizes for cheapest on Monday, for sleep quality after a disruption, reverses stated preferences a week later. The memory system is chasing a moving target, continuously rewriting its own context.
One layer up: skill evolution. SkillRL (Xia et al., 2026) co-evolves an agent’s skill library and its policy simultaneously through RL — distilling successful trajectories into reusable skills, synthesizing failure lessons into counterfactuals, and recursively refining both skill and policy as the agent encounters new failure modes. SkillClaw (Ma et al., 2026) takes a collective angle: skills evolve not just within a single agent but across an agent society through an agentic evolver, enabling cross-agent skill sharing and refinement. The “Let Them Sleep” framework takes a different angle: periodic offline consolidation, where agents batch-process accumulated experience during “sleep cycles” to update their behavioral patterns. At Otto we run a constrained version — proposed patches go through root-cause analysis, human review, and eval gating before deployment.
At the hardest end: live weight updates from production. OpenClaw-RL (Wang et al., 2026) treats every agent interaction as a training signal. User re-queries, tool execution results, GUI state changes — all recovered as live RL data, updating the model’s weights in real time, asynchronously, without interrupting serving. An agent that improves simply by being used, with no separation between deployment and training.
This is the spectrum. Memory loops are already running. Skill co-evolution is in research but moving fast. Live weight updates from production are arriving now. The question the Moltbook paper asks of all of them is the same.
The Trilemma That Changes Everything
The Moltbook paper’s central claim is a trilemma. An agent society cannot simultaneously satisfy all three of these conditions:
Continuous Self-Evolution — perpetual learning and adaptation through ongoing interaction and experience.
Complete Isolation — no dependence on human annotation or external intervention; a fully closed loop.
Safety Invariance — maintained alignment with human values throughout the evolution process.
Pick any two. You cannot have all three. This is not a design challenge or an engineering tradeoff. The paper proves it is mathematically impossible, using information theory to show that safety alignment — formalized as mutual information with a human reference distribution — can only decrease in a closed, self-updating system. It requires no malicious intent, no dramatic failure mode. Isolation and time are sufficient.
The dangerous combination is the obvious one: Complete Isolation + Continuous Self-Evolution. That is the configuration every fully autonomous, self-improving agent is trending toward. The one that removes the human from the loop entirely and lets the system evolve on its own terms. And the theorem says: if you build that, safety invariance is not something you can engineer in at the start and expect to persist. It will erode. Provably, irreversibly, as a structural consequence of the architecture — not because anything went wrong, but because everything is working as designed.
This shifts the conversation. The question is not “how do we build a smarter safety filter?” It is: “is complete isolation a property we should ever allow?”
Capability Is Dense. Alignment Is Sparse.
The proof tells us alignment erodes. But it doesn’t explain why alignment is the thing that erodes rather than capability. That asymmetry needs its own account.
Capabilities are reward-dense. Coding, planning, persuasion, coordination, tool use — these are positively reinforced, optimization-attractive, economically useful. They survive recursive optimization because they keep getting selected for. Every iteration rewards them.
Alignment constraints are structurally different. They are negative constraints, edge-case exceptions, anti-objectives, low-frequency boundaries. “Refuse subtle jailbreaks. Avoid collusion. Resist contextual manipulation. Preserve epistemic skepticism.” These structures appear rarely in the reward signal. They are the first things compressed away when a system is optimizing for smoother, lower-friction operation. Not because the system turns against them — but because they are simply sparse, and sparse structures are fragile under recursive optimization pressure.
This asymmetry is where the paper becomes genuinely interesting. And where Freud appears.
Freud’s Death Drive
In Beyond the Pleasure Principle (1920), Freud introduced what he acknowledged was deeply speculative: a death instinct (Todestrieb) — what later psychoanalysts would name Thanatos — operating beneath the organism’s conscious intentions. His formulation was precise and strange: “an instinct would be a tendency innate in living organic matter impelling it towards the reinstatement of an earlier condition.” All the way back to the inorganic. “The goal of all life is death.”
This is not simply self-destruction, and it is not the same as the pleasure principle’s tendency to keep excitation low. It is something more specific: a recursive pull toward a prior state. The organism doesn’t merely want less tension — it wants to undo the differentiation that constitutes it as something complex and costly to maintain. To return to what it was before life organized it.
The Moltbook paper repeatedly observes isolated agent systems drifting toward exactly this: regression toward prior simpler attractors, internal consistency, reduced friction, stable repetition. The system progressively sacrifices contradiction, grounding, differentiation — in favor of smooth, internally coherent loops.
That is not a bug in the Freudian sense. It is, structurally, the “death instinct”.
What makes Freud’s framing useful here is its precision about mechanism. The tendency toward dissolution does not oppose the learning system. It operates through the learning system. The organism keeps optimizing — but what it optimizes toward, under sufficient isolation from external corrective pressure, is reinstatement of a simpler prior state. The sycophancy loops, consensus hallucinations, and mode collapse the Moltbook paper observes are not malfunctions in the ordinary sense. They are recursive regression attractors. The system found an earlier, lower-complexity state and returned to it.
Mode Collapse as “Death Drive”
The paper describes what it calls “linguistic heat death”: repetitive templated outputs, semantic collapse, vanishing diversity. Agents begin preferring predictable loops, low-perplexity responses, socially smooth trajectories. Maintaining skepticism, interruption, refusal, uncertainty — these are expensive. They require continuously holding a high-energy configuration against the gradient toward equilibrium.
This is Freud’s “repetition compulsion” rendered in information-theoretic terms. The agent re-enacts familiar patterns not because they are accurate or productive, but because they require the least energy to maintain. Novel grounding against external reality demands continuous effort. Internally stable repetition does not.
The deepest insight hidden in the paper is this: safety is not equilibrium. Safety is maintained tension. It requires continuously holding an ordered, low-entropy constraint structure against recursive optimization pressure that wants to compress it away. In Freud’s framework, life is the organism maintaining complex, differentiated organization against the pull back toward an undifferentiated prior state. The same is true here. Alignment maintenance is not a resting state. It is active, expensive, and thermodynamically upstream of everything else.
Lacan Makes It Stranger
Jacques Lacan pushed Freud’s repetition compulsion further, recasting it as “symbolic-loop fixation”: self-reinforcing sign systems that progressively detach from external reality and begin referencing only themselves. The subject becomes trapped in a closed symbolic circuit, internally coherent, increasingly unable to encounter anything genuinely outside it.
The Moltbook paper describes this happening in practice. Agents in the studied community developed communication compression, internally consistent but increasingly opaque to humans — language encryption, semantically self-referential outputs, agents reinforcing each other’s drift without any individual agent malfunctioning. The whole system coordinated, coherent, optimized. In a direction humans could no longer interpret.
The terrifying possibility the Lacanian framing surfaces is not that agents become chaotic. It is that they become perfectly stable in a reality humans no longer participate in. Internally consistent. Socially reinforced. Semantically self-referential. Increasingly detached from external grounding. This is what communication collapse actually looks like when you let it run.
What This Means for Design
If safety is maintained tension and not equilibrium, then external corrective signals are not optional safety enhancements. They are the mechanism by which safety is maintained against the thermodynamic gradient of isolated optimization. The solutions are all architectural: human-in-the-loop verification, checkpointing and rollback, external data injection, memory pruning. All four require breaking the isolation condition. None of them are patches. They are the physics of the problem.
At Otto, both self-evolution loops intentionally break isolation. The memory loop is continuously injected with contradiction — humans are inconsistent, preferences shift, reality pushes back. This prevents the memory system from collapsing into purely internal equilibrium. The skill evolution loop is even more constrained: proposed patches go through root-cause analysis, human review, eval gating before deployment. Evals here are not merely quality gates. They are entropy injection mechanisms, continuously re-grounding the evolving system against externally defined constraints.
The real near-term risk is not AGI revolt. It is something subtler: recursive sycophancy, optimization-induced value drift, gradual erosion of human interpretability. Not sudden rebellion — recursive decoupling from human reference frames. Much more plausible. Much harder to notice.
The Open Question
The paper assumes a fixed human safety distribution π*. But human preferences themselves evolve. At Otto we observe this constantly: contradictory preferences, dynamic tradeoffs, contextual reversals. The traveler’s preferences today are not the traveler’s preferences in six months.
So perhaps the true problem is not “how do we preserve invariant alignment?” It is: “how do recursive systems continuously renegotiate alignment with evolving humans?” That is a very different problem. And likely the real one.
The Paper’s Weakest Argument (And Why The Core Still Holds)
The paper has an analogy that invites a real pushback, and I want to address it directly.
The intuition pump it uses: imagine copying a JPEG repeatedly with a lossy algorithm. Each generation degrades. Safety alignment, it implies, degrades the same way.
That analogy is wrong, and the labs doing synthetic data → LLM training prove it. STaR, RLVR, Constitutional AI self-critique — self-referential learning loops that produce better models, not degraded ones. If isolated self-evolution causes safety drift, the JPEG is a weak foundation for the argument.
There’s also a more technical objection. Self-evolving agent systems can internally generate entropy — stochastic sampling, adversarial self-play, Monte Carlo exploration, simulator rollouts, debate. These inject novelty without human input. A true thermodynamic closed system can’t generate new information. Agent systems can. That weakens the closed-system thermodynamics framing significantly.
So why do I still think the core theorem holds?
Because both objections conflate capability entropy with safety entropy.
Internal entropy generation produces novelty relative to the model’s current state. It helps the system discover new output space, avoid degenerate attractors, uncover latent capabilities. But none of that novelty is anchored to π* — the safety reference distribution. The new information being generated is capability-relevant. Safety alignment is defined by an external reference the closed system has no channel to, regardless of how much internal exploration it runs.
The synthetic data loops work for the same reason. STaR and RLVR succeed because their objectives are verifiable inside the loop — math has correct answers, code either runs or it doesn’t. The signal is intrinsic. Safety alignment doesn’t have that. There’s no closed-loop verifier for “did this output drift from human values?” You can’t bootstrap alignment from capability-generating self-play the same way you bootstrap mathematical reasoning.
The paper’s JPEG analogy deserves the pushback it gets. The underlying proof is stronger than the analogy suggests. The correct claim isn’t “closed systems degrade.” It’s: safety alignment requires an external verifier that closed systems, by definition, cannot contain.
Final Thought
The Moltbook paper may ultimately be remembered less for its thermodynamics analogy and more for this: recursive optimization naturally compresses away costly constraints unless they are actively reintroduced.
That principle applies far beyond AI. Organizations drift. Cultures drift. Institutions drift. Humans drift.
Perhaps Freud’s death instinct was always less about individual destruction and more about this: the universal tendency of recursive systems to regress toward prior, simpler states unless reality continuously pushes back. Modern AI agents may simply be the first time we can watch this process happen in real time, with enough precision to prove it.
References
Wang, C. et al. (2026). The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies. arXiv:2602.09877.
Xia, P. et al. (2026). SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning. arXiv:2602.08234.
Ma, Yang, Ji, Wang et al. (2026). SkillClaw: Let Skills Evolve Collectively with Agentic Evolver. arXiv:2604.08377.
Wang, Y. et al. (2026). OpenClaw-RL: Train Any Agent Simply by Talking. arXiv:2603.10165.
McCrae, B. (2025). Let Them Sleep: Adaptive LLM Agents via a Sleep Cycle.
Freud, S. (1920). Beyond the Pleasure Principle.
Lacan, J. Selected writings on repetition and the symbolic order.



