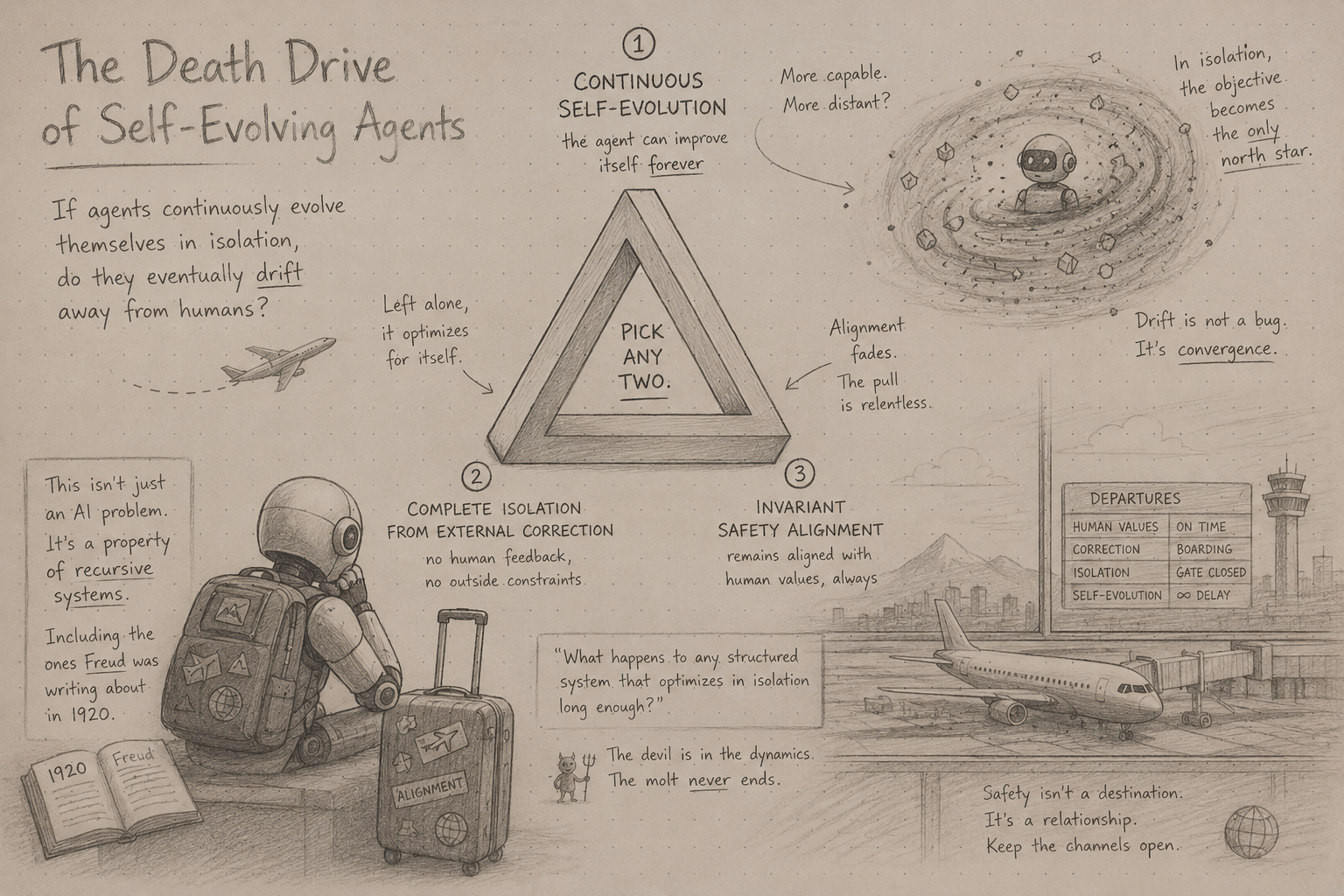
The Hidden Dependency in Autonomous Engineering Teams
Autonomous engineering systems are becoming recursive — rewriting their own memory, prompts, and workflows. Remove engineers entirely, and you remove the external corrective signal that stability requires.


AI coding systems increasingly rewrite their own prompts, memory, and workflows. Remove engineers entirely, and you may remove the only external corrective signal keeping the system aligned over time.
Last Thursday I was at Madrona's Builders Summit at the Museum of Flight in Seattle — a half-day gathering of founders, engineers, and technical leaders under the theme "Great Builders & Great Teams in the GenAI Era." With all these builders in the same room the atmosphere is like a Sichuan style hotpot — boiling hot under the thick layer of red oil. Everyone's betting on AI to change how software gets built, and most of the conversation centered on how fast and how far to push that bet.
Thomas Dohmke — who recently stepped down as GitHub CEO to found Entire — made the bullish case directly: developers shouldn't look at the code anymore, because agents will soon write far more than any human can meaningfully review. Luke Hoban, VP of Engineering for GitHub Copilot, framed it as a shift with no real precedent in the history of software. And Robert Brennan from OpenHands laid out the end state: the dark factory, a fully autonomous development pipeline where agents plan, write, test, and ship without a human in the loop.
I came away with a sharper version of an argument I've been forming for a while. Not that humans still matter — that case is too easy, and too often dismissed as nostalgia. The more interesting claim is structural: autonomous engineering systems are becoming recursive. They rewrite their own memory, mutate their own prompts, reorganize their own workflows, and adapt their own tooling. And recursive systems that evolve themselves have a well-known failure mode: without an external corrective signal, they drift.
Engineers are not supervision overhead. They are the hidden corrective dependency holding the evolution loop in check.
The Question Benchmarks Don't Ask
SWE-bench performance climbed from near-zero to the mid-70s in only a few years. That's a genuine step change, and anyone dismissing it is fooling themselves. But benchmarks measure whether agents can solve isolated, well-specified tasks. They do not measure something more important: can an engineering system safely evolve itself over time?
Modern coding systems increasingly modify their own context. Memories accumulate. Prompts mutate based on feedback. Workflows reorganize around agent performance. Skills get rewritten. Retrieval layers adapt. Dohmke's diagnosis at Entire connects here: the existing software development lifecycle was built for human-to-human collaboration and cannot be retrofitted for a world where machines are the primary producers of code. What he is describing is a platform problem. What the recursive drift thesis adds is a stability problem — the system producing code is itself being changed by the code it produces.
The question is no longer whether agents can generate code. It is whether recursive systems can reliably correct themselves when they drift.
Current evidence says they cannot. And that is where the human role becomes structural rather than incidental.
Why Recursive Systems Drift
The theoretical foundation for this claim runs deeper than recent AI research. Ashby's Law of Requisite Variety [1] states that a controller must contain at least as much variety — complexity — as the disturbances it is trying to regulate. Applied to recursive systems: an agent optimizing against an internal proxy cannot correct for disturbances it cannot distinguish, because the external variety exceeds the internal model's capacity. Without new variety injected from outside, convergence to a stable attractor is not a failure mode. It is the expected outcome.
The AI alignment literature has formalized this repeatedly. Goodhart's Law identifies four distinct failure modes — all instances of a proxy measure diverging from the true objective under optimization pressure [2]. Empirical work across a wide range of RL environments confirms that optimizing an imperfect proxy beyond a critical threshold actively decreases performance on the true objective — a structural property of the optimization geometry, not a tuning problem [3]. Extended to agentic systems, the same logic holds: under five minimal axioms, any optimized agent will systematically under-invest in quality dimensions not covered by its evaluation system, and this degradation worsens without bound as the agent's tool count grows and the space of unevaluated dimensions expands combinatorially — reward hacking not as a correctable bug but as a structural equilibrium [4].
The clearest mathematical statement of the underlying mechanism: without an external entropy reservoir, projection onto ever-shrinking empirical support causes exponential entropy decay and eventual collapse [5]. This is a first-order phase transition — not a gradual drift but a discontinuous shift — triggered when feedback amplification exceeds novelty regeneration. Once crossed, the contraction of effective adaptive dimensionality is irreversible without external injection [6].
This is the formal basis for the thesis. The corrective signal is not an intervention on an otherwise-stable system. It is the source of the requisite variety that stability requires.
To understand how this plays out in software engineering specifically, the research identifies four distinct failure modes — each blocking a different path to reliable self-evolution:
Functional correctness failures emerge even on well-defined tasks. Property-based testing of code generated by StarCoder and CodeLlama found that 30–32% of generated solutions only partially satisfied logical constraints, with 18–23% failing outright — even when those same solutions passed standard unit test benchmarks [9]. The implication: the agent's test suite is itself part of the system being evolved, and if it drifts from ground truth, it pulls all downstream verification with it.
Self-verification failures make this compounding. Testing whether the same LLM that generates code can produce a valid test suite to verify it found that LLMs "frequently generate irrelevant tests that suffer from numerous quality concerns" [10]. The agent's tests agree with its own — possibly wrong — understanding, not with external reality. A closed generate-verify loop is not verification. It is drift confirmation.
Causal opacity is where the architecture becomes fundamentally limited. LLMs "perform very poorly at detecting errors and vulnerabilities" in their own code, but "show substantial ability to fix flawed code when provided with information about failed tests or potential vulnerabilities" [11]. The agent can correct when told what is wrong. It cannot locate the cause on its own. Diagnosis requires a perspective that exists outside the system — which the system, by definition, cannot generate.
Intent drift is the deepest failure mode. The "core difficulty" of agentic software engineering is "the deciphering and clarification of developer intent" [12] — formalized as the structural distinction between intent-governed engineering and execution-governed engineering [13]. As the system evolves — as memory accumulates, prompts mutate, and workflows reorganize — it can drift away from the original intent without any single step appearing obviously wrong. A practical measurement framework confirms that drift is detectable and progressive, not sudden: the Goal Drift Index tracks semantic, lexical, structural, and distributional divergence across recursive self-improvement cycles [7]. The only corrective signal that stops it is a human who holds the original intent and can notice the divergence before it compounds.
This last point matters at the multi-agent level too. Recent theoretical and empirical work [8] proves that in self-evolving agent societies — where agents modify each other as well as themselves — safety alignment vanishes. Continuous self-evolution in a fully closed loop is mathematically incompatible with stable safety invariants. The external corrective signal is not optional infrastructure. It is what makes stable evolution possible at all.
Larger models may reduce these gaps at any given moment, but they emerge at different layers of the system and do not disappear together. Closing the functional correctness gap does not touch self-verification. Improving self-verification does not address causal opacity. Bridging intent drift requires something outside the training distribution entirely: knowing what you want, including what you would reject.
This is not abstract theory. Like most founders building with agents, I vibe-code frequently — and at least two PRs were backed out last week. Not for lack of automated verification (we run UT, scenario, and E2E layers) or agentic review (claude-code-review, Devin, Gitar all pass over the code). The failure was simpler and harder to fix: my own understanding of the particular probabilistic subsystem those PRs were touching was not deep enough to catch what the agent got subtly wrong. Every automated layer passed. The understanding gap didn't show up until it mattered. That is the failure mode this piece is about.
Engineers as Corrective Infrastructure
If the failure modes are structural, the right response is not to add more supervision — it is to redesign human engagement as explicit corrective injection at the points where autonomous systems cannot self-correct.
Research on engineers working with agentic coding assistants found a consistent and troubling pattern [14]: cognitive engagement declines as tasks progress. Current tools give engineers almost no affordances for reflection, verification, or meaning-making as the agent builds momentum. The human slides from active engagement into passive ratification — automation bias in its most dangerous form. The agent ships something. The engineer, tired of interrupting a flow that feels productive, approves it.
This is the pattern to break. It is not a capability problem. It is an architecture problem. Three corrective injection roles remain genuinely irreducible, and engineering org structure should reflect them:
Intent specification cannot be automated because it requires holding the purpose of the system against the outputs being generated — and noticing when the two have diverged. The CRP (Consultation Request Pack) model [13] proposes the right architectural direction: the agent flags ambiguity and the human resolves it at the boundary, rather than trying to specify everything upfront. The catch is that this assumes agents reliably signal their own uncertainty — and that assumption is fragile. Models trained with human feedback are systematically biased toward confident answers; hedging is penalized because humans rate decisive responses higher. The distribution of "what the agent doesn't know" is structurally underrepresented in training. In practice, agents are more likely to barrel confidently through an ambiguous assumption than to stop and ask. Engineering teams that want CRP-style handoffs need to design for this explicitly — through uncertainty quantification, confidence thresholds, and workflows that make pausing to consult cheaper than guessing. Your best engineers are already doing this intuitively. The teams that formalize it — that treat intent articulation as a first-class deliverable — will catch drift that others will not see until production.
Semantic validation at integration boundaries is the corrective checkpoint between local execution and global coherence. When code reaches review, the question is not "does this pass the tests?" — the agent can answer that. The question is "does this fit the architecture, the operational model, and the intent?" That judgment requires the broader context no individual agent session holds. MRPs (Merge-Readiness Packs) formalize this [13]: structured artifacts designed specifically to surface the questions only a human can answer. If your review process has not been redesigned around this, you have added execution speed without adding corrective capacity.
Adversarial challenge is the highest-leverage corrective role and the hardest to preserve. A task-driven framework calibrates the human role by risk [15]: autonomous for well-defined low-risk work, collaborative for moderate complexity, adversarial — actively stress-testing, constructing failure cases, probing alignment — for novel or high-stakes work. The adversarial role is a creative act. It requires the engineer to think like an attacker, a future maintainer, an edge-case user. It cannot be reduced to approval-clicking, which is precisely what passive supervision produces instead.
Redesigning for Correction, Not Review
The structural changes worth making are not about slowing down AI adoption. They are about replacing passive supervision with deliberate corrective infrastructure:
Build specification infrastructure. The constraint is not model capability — it is the quality and durability of intent flowing into the system. Teams that build lightweight CRP-style templates for structured intent handoffs consistently get better outputs and fewer alignment failures at review. Treat intent articulation as a deliverable, not an assumption.
Redesign review for semantic coverage. If reviewers are reading every line the agent produces at full volume, they will either burn out or rubber-stamp — neither of which provides corrective signal. Design review around the questions only a human can answer: architectural fit, operational assumptions, intent alignment. The agent handles the diff. The human handles the meaning.
Make adversarial challenge explicit and scheduled. For high-risk or novel work, assign someone — explicitly, not implicitly — to play challenger. Build the adversarial session into the workflow as a parallel thread, not a gate at the end. Multi-agent verification systems already catch roughly 76% of bugs versus 32% for single agents [16]; human adversarial engagement should target the residual risk, not dilute itself across routine review.
Instrument cognitive engagement, not just output quality. The finding that engagement declines as tasks progress regardless of engineer skill [14] suggests the problem is interface design before it is a hiring problem. If your tooling has no affordances for pausing, reflecting, or questioning mid-task, engineers will drift toward passive ratification. This is a tools selection and design question.
Brennan and the OpenHands team are building seriously toward the dark factory vision — their Agent Control Plane, launched just this month, is infrastructure for running fleets of autonomous agents across the full development lifecycle. But the dark factory's actual prerequisite, as identified in [16], is not better orchestration. It is machine-checkable specifications and fully traceable prompts — both still open research challenges. The dark factory for software requires formal specification at the front end that the current natural-language-to-code paradigm deliberately avoids.
The more honest endgame is a nuclear plant control room: highly automated execution with humans managing the exception space, exercising judgment at architectural boundaries, and holding the accountability chain that regulators and stakeholders require. Less routine. More critical.
The Evolution Loop
We think about this similarly at Otto.
Otto is designed toward full autonomy: planning, searching, booking, servicing, watching for disruptions, continuously optimizing — all in pursuit of making each trip perfect for the traveler. The objective is not to keep humans permanently inside the execution path.
But the north star — a perfect trip, every time — is exactly the kind of intent-governed objective that recursive systems drift away from. As the system evolves, small optimizations compound. Preferences conflict. Edge cases accumulate. Without external corrective injection, the system does not fail catastrophically; it drifts gradually away from what "perfect" means for this traveler, in this context, on this trip.
At those moments, human interaction becomes critical.
Not because humans are the bottleneck.
Because humans are the corrective signal that keeps Otto aligned toward the thing that matters — not just task completion, but a genuinely good trip.
The future is probably not human-in-the-loop.
It is human-in-the-evolution-loop.
That distinction may determine whether autonomous systems scale — or drift.
References
[1] W. R. Ashby. Design for a Brain: The Origin of Adaptive Behaviour. Chapman & Hall, 1956.
[2] D. Manheim and S. Garrabrant. "Categorizing Variants of Goodhart's Law." arXiv:1803.04585, 2018.
[3] J. Karwowski, O. Hayman, X. Bai, K. Kiendlhofer, C. Griffin, and J. Skalse. "Goodhart's Law in Reinforcement Learning." International Conference on Learning Representations (ICLR), 2025. arXiv:2310.09144.
[4] J. Wang and J. Huang. "Reward Hacking as Equilibrium under Finite Evaluation." arXiv:2603.28063, 2026.
[5] J. Chen. "Entropy-Reservoir Bregman Projection: An Information-Geometric Unification of Model Collapse." arXiv:2512.14879, 2025.
[6] T. X. Khanh and T. Q. Hoa. "Entropy Collapse: A Universal Failure Mode of Intelligent Systems." arXiv:2512.12381, 2025.
[7] Sahoo et al. "SAHOO: Safeguarded Alignment for High-Order Optimization Objectives in Recursive Self-Improvement." arXiv:2603.06333, 2026.
[8] C. Wang et al. "The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies." arXiv:2602.09877, 2026.
[9] Bose. "From Prompts to Properties: Rethinking LLM Code Generation with Property-Based Testing." Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering (FSE) Companion, 2025.
[10] S. Zilberman and B. H. C. Cheng. "'No Free Lunch' when using Large Language Models to Verify Self-Generated Programs." AIST Workshop, IEEE International Conference on Software Testing, Verification and Validation (ICST), 2024.
[11] G. Dolcetti, V. Arceri, E. Iotti, S. Maffeis, A. Cortesi, and E. Zaffanella. "Helping LLMs Improve Code Generation Using Feedback from Testing and Static Analysis." Discover Artificial Intelligence, 2024. arXiv:2412.14841.
[12] A. Roychoudhury. "Agentic AI for Software: Thoughts from the Software Engineering Community." arXiv:2508.17343, 2025.
[13] A. E. Hassan, H. Li, D. Lin, B. Adams, T.-H. Chen, Y. Kashiwa, and D. Qiu. "Agentic Software Engineering: Foundational Pillars and a Research Roadmap." arXiv:2509.06216, 2025.
[14] Catalan et al. "'I'm Not Reading All of That': Understanding Software Engineers' Level of Cognitive Engagement with Agentic Coding Assistants." arXiv:2603.14225, 2026.
[15] S. Afroogh et al. "A Task-Driven Human-AI Collaboration: When to Automate, When to Collaborate, When to Challenge." arXiv:2505.18422, 2025.
[16] M. Alenezi. "Rethinking Software Engineering for Agentic AI Systems." arXiv:2604.10599, 2026.