When Multi-Agent Systems Don’t Scale and Lessons for Vertical AI
No, multi-agent-system is not the ultimate solution. And before we reach the cheesy answer of "hybrid", let's break it down of what makes MAS great and not so great first.

Over the last 18 months, “multi-agent systems” have become one of the most popular explanations for how AI will escape the limits of chat interfaces and turn into problem-solving engines. The pitch is straightforward: instead of one giant model doing everything, deploy multiple specialized models that coordinate like a team.
It’s a powerful idea - but also a misleading one.
A new paper titled “Towards a Science of Scaling Agent Systems” (arxiv: 2512.08296) takes a welcome step away from slogans and toward measurement. The authors ask a question that surprisingly few people have asked out loud:
Under what conditions do multi-agent systems actually outperform single-agent systems?
The answer, once measured, is far from universal. Multi-agent systems (MAS) outperform single-agent systems (SAS) in some cases, fall flat in others, and actively degrade performance in certain regimes that are common in real-world applications.
For people actually building agentic systems - especially in verticals like travel, finance, logistics, or operations - this is the kind of grounding the ecosystem needs.
What Counts as an Agent?
Before comparing single-agent systems (SAS) and multi-agent systems (MAS), it’s important to define what an “agent” even is in this context.
An agent is not just an LLM; it is,
… language model-driven systems that operate through iterative cycles of reasoning, planning, and acting, adapting their behavior based on environmental or tool-generated feedback…
In other words, it is a loop that:
- observes the environment,
- decides what to do next,
- acts via tools or APIs, and
- updates its internal state or world model.
.jpg)
The key point is that agents operate in an environment, not just on text. They receive feedback, make decisions, and execute actions that may change the world in order to achieve its assigned task.
With that definition:
- A single-agent system (SAS) is one decision-making locus driving all observations, decisions, and tool calls.
- A multi-agent system (MAS) has multiple decision-making loci that may specialize, coordinate, debate, or validate each other.
We’re not looking at merely “one model vs many models”, or number of components/modules/loops. At the end of day, it’s one control policy vs many policies interacting with the environment and each other.
Three Axes that Actually Matter
DeepMind frames agent performance as a function of three independent axes:
- Model capability (Is the single agent already strong?)
- Task decomposability (Can the task be parallelized?)
- Tool richness / coordination load (How much external environment must be orchestrated?)
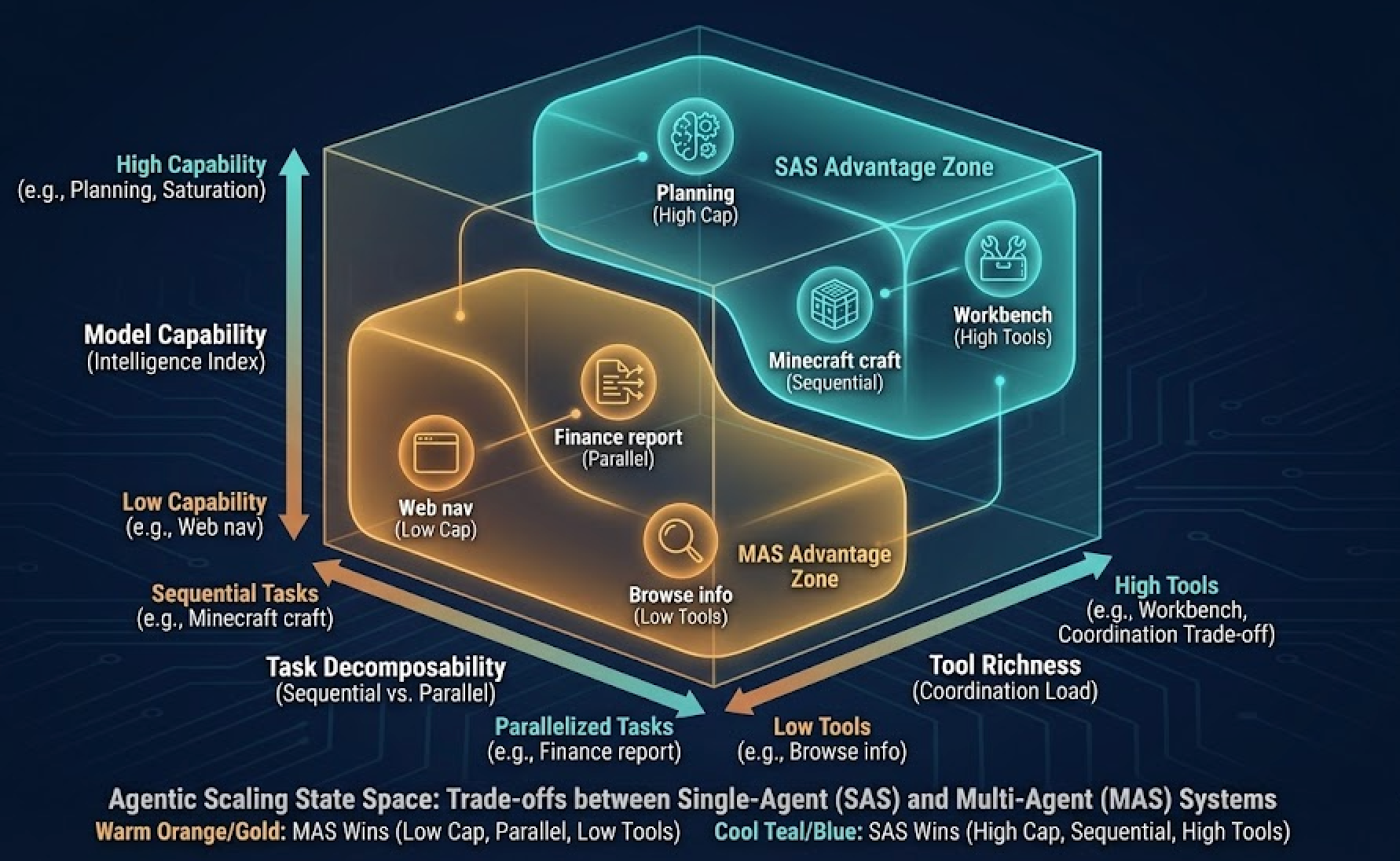
These are deceptively simple, but they explain most observed variations.
When model capability is high, single-agent performance saturates. When tasks are parallelizable, multi-agent wins. When external tools require strict ordering or shared state, multi-agent collapses under coordination overhead.
This already contradicts a lot of the casual claims floating around the agent development community, that multi-agent system being an automatic “scaling path.” It isn’t. It depends on what you are scaling.
Five Findings Worth Calling Out
Here are five empirical findings from the paper, each followed by our practical interpretation for builders.
1. Multi-agent benefits are task-contingent
The dominant finding is simply that MAS can outperform SAS - but only when the task admits parallelism and the single agent baseline is weak enough to benefit from division of labor.
In their Finance-Agent benchmark, multiple agents slice financial analysis into independent sub-tasks and converge on a final answer. MAS outperforms SAS by large margins because the model can explore multiple hypotheses and aggregate.
Builder’s takeaway:
Parallel cognition is a legitimate scaling vector - when tasks are decomposable and tool-light. Think brainstorming, option evaluation, research, or simulation.
2. Parallelism benefits decomposable tasks
This seems obvious, but the devil is in what counts as “decomposable.” Evaluating 200 flight options in parallel is decomposable. Booking a single flight is not.
MAS becomes a cognitive cluster, like map-reduce for reasoning. SAS must process options sequentially.
Builder’s takeaway:
If the task graph has wide fronts (many independent nodes), MAS makes sense. If it has long chains (dependencies), MAS stalls.
3. Sequential constraint kills MAS
The negative result is more important than the positive one: tasks with sequential dependencies actively punish multi-agent architectures. DeepMind’s Minecraft PlanCraft benchmark showed a −39% to −70% degradation for MAS compared to SAS.
The reason isn’t that agents are “dumber.” It’s that the environment enforces serialization. To build a furnace in Minecraft, you need coal and cobblestone; to get those, you need tools; to get tools, you need wood. The dependency graph is basically a DAG with tight ordering.
Parallel actors just trip over each other.
Builder’s takeaway:
If reality forces serialization, MAS doesn’t magically parallelize it.
4. Validation bottlenecks matter
The paper also compared different MAS topologies: independent, centralized, decentralized, and hybrid. Independent MAS looked good on paper but failed catastrophically in practice due to error accumulation. Without arbitration or validation, wrong intermediate outputs cascade and amplify.
Centralized or hybrid systems performed significantly better because they had a critic, planner, or orchestrator that could prune bad paths.
Builder’s takeaway:
Multi-agent systems need high-quality validation to avoid compounding entropy. Without it, you’re just parallelizing errors.
5. Tool-rich tasks favor SAS
This is the part most relevant to real-world deployment. Tool use sounds like a feature (“agents can act!”) but it introduces latency, shared mutable state, and strict serialization points. In the Workbench benchmark, tool calls dominate runtime and coordination. MAS ends up waiting on itself.
SAS, by contrast, can perform the classic loop:
act → observe → update → act →
with no arbitration overhead.
Builder’s takeaway:
Tool use makes MAS look more like a distributed transaction coordinator. At some point it’s cheaper to just let one capable agent drive the bus.
The Architecture Selection Rule
The authors propose an implicit decision rule:
Choose MAS only when decomposition + low tool complexity + low SAS baseline align.
When SAS is strong, tools are heavy, or tasks are serial, MAS does not outperform, or worse, often underperforms.
This is the kind of heuristic that builders like you and me can use. And it maps almost perfectly onto what we’ve seen at Otto.
Where Otto Sits in This Landscape
At Otto, we built an AI executive assistant for business travelers. It needs to search, compare, apply policies, and ultimately book and service flights and hotels across real inventory with real consequences.
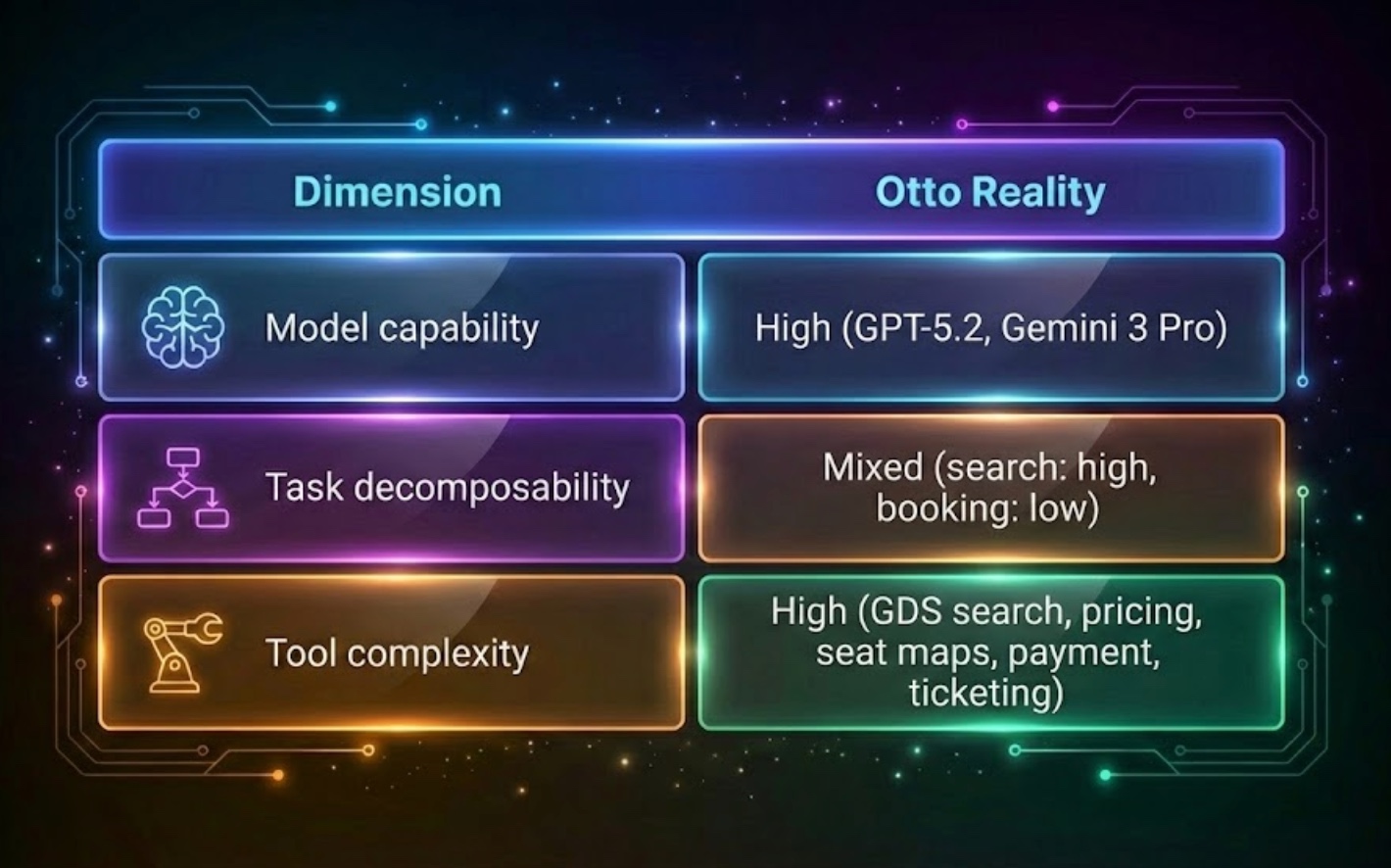
This leads to a very pragmatic architectural conclusion:
- Parallel MAS is useful during the reasoning phase: ranking itineraries, comparing hotels, applying policy constraints, estimating risk, or modeling loyalty value.
- SAS is superior for the transactional phase: outbound → inbound → seat selection → baggage → payment → ticketing → confirmation.
This is why Otto uses a hybrid architecture: MAS for cognitive breadth, SAS for transactional correctness. DeepMind’s paper doesn’t prescribe this hybrid design, but it basically explains why we converged on it.
The Future: Vertical Agent Systems Will Not Be Fully MAS
The discourse today often imagines MAS as the future of agentic AI, with SAS as an older abstraction. DeepMind’s results suggest the opposite for vertical domains:
- The more tool-rich, regulated, mission-critical, and transactional the environment,
- The more important orchestration, validation, and serialization become.
In that world, MAS is not the destination - it’s a technique. The destination looks more like:
hierarchical SAS + selective MAS + strong validation + real-world tools
And zooming out, the core lesson for builders is straightforward:
Scaling is not just about compute; it’s about topology and environment.
This aligns with what deep vertical AI ultimately requires: not “more agents,” but more correct agents that can safely operate against live systems with real users and real money.



