CL-Bench Says Frontier Models Struggle With Context Learning
If LLMs can’t reliably learn from in-context learning, agents must do more to deal with the weakness. This post explains how Otto structures reasoning and verification to make AI agents work in the real world.


...And How Should We Design AI Agents to Avoid These Weaknesses?
A recent paper, CL-Bench: A Benchmark for Context Learning (arxiv: 2602.03587), made a provocative claim:
Frontier language models still lack true context learning ability.
Their benchmark shows that even the best frontier model solves only 23.7% of tasks, while the average across models is 17.2%.
This raises an important question for anyone building AI agents:
If frontier models struggle to learn and reason from context, how should we design AI agent systems to maximize success and avoid the weaknesses of the underlying models without post training?
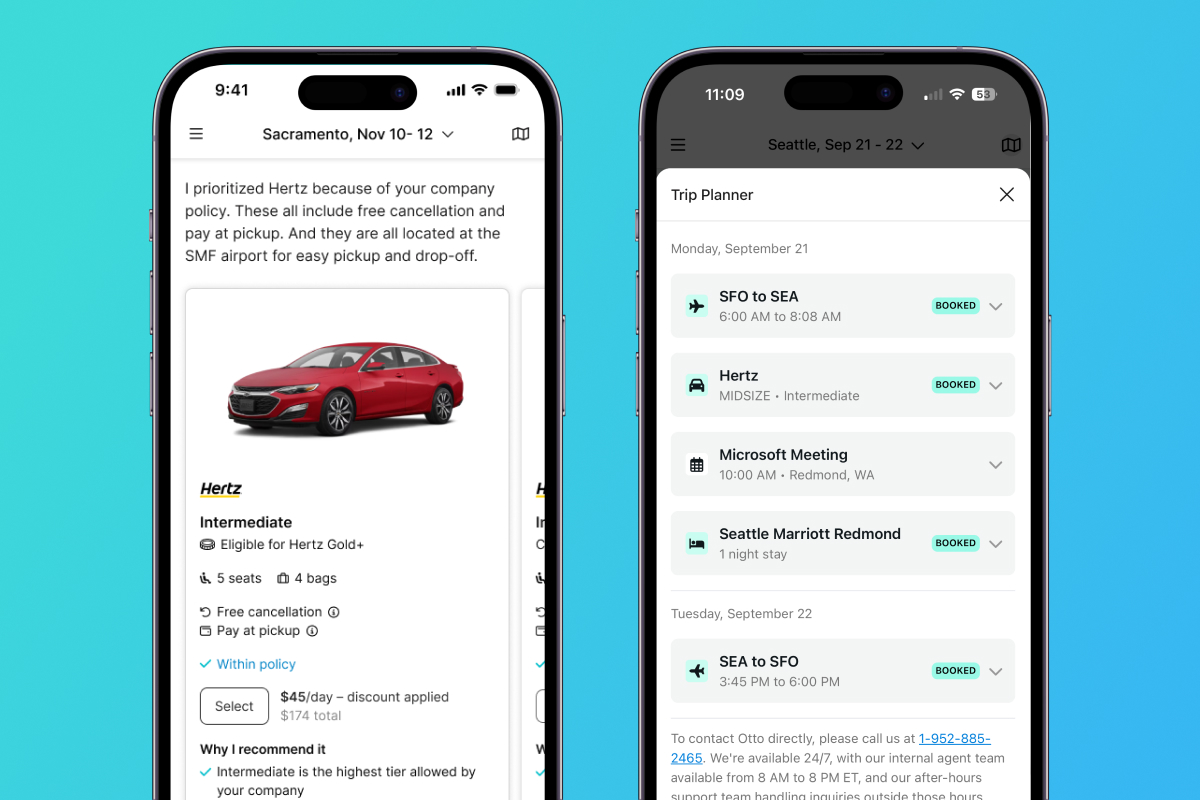
This question matters deeply for systems like Otto, an AI executive assistant for travel designed to organize complex trips while respecting traveler preferences, corporate policies, and optimization constraints.
In this post, I’ll share my thoughts on the following subjects:
- What CL-Bench actually measures
- Why the results are insightful but not perfectly clean
- What these findings mean for real-world AI agents
- How we design Otto to mitigate these limitations
What CL-Bench Actually Studied
The CL-Bench paper argues that current LLM development focuses on prompt reasoning using pre-trained knowledge, while real-world tasks require learning new knowledge from context.
The authors call this capability:
Context Learning
Meaning:
Learn new knowledge from context
+
Apply it to solve tasks
They built a benchmark with:
- 500 contexts
- 1,899 tasks
- 31,607 evaluation rubrics
Each context contains domain material such as:
- product manuals
- research papers
- operational workflows
- rule systems
- experimental data
Tasks then require the model to learn from this material and apply it.
The benchmark divides contexts into four categories:
- Domain knowledge reasoning
- Rule system application
- Procedural task execution
- Empirical discovery and simulation
The last category is particularly difficult because it requires inductive reasoning rather than applying explicit rules.
The Main Result
Across ten frontier models, performance is surprisingly low.
Average solve rate: 17.2%
Best model: 23.7%
No model reaches even 30% success.
Error analysis reveals the dominant failure modes:
Context ignored: ~55–66%
Context misused: ~60–66%
Format errors: ~33–45%
In other words:
Foundational models frequently have the relevant information in context but fail to use it correctly.
The benchmark also shows two structural challenges:
- Long contexts degrade performance
- Inductive reasoning is significantly harder than rule application
These results suggest that context learning remains a major bottleneck for LLMs.
But the Benchmark Is Not Perfectly Clean
While the results are important, I personally would be cautious when interpreting them.
The benchmark assumes that contexts contain new knowledge absent from pretraining.
However, I see a fundamental problem here:
There is no such thing as a completely “clean” new concept in natural language.
Every concept expressed in language uses existing words with prior meanings.
For example:
"In this fictional system gravity pulls upward."
Even though the rule is new, the words:
gravity
pull
upward
... already carry semantic priors.
So the model is not learning a completely new concept.
Instead it must do something harder:
Override prior knowledge
+
Adopt a new relationship described in context
This means CL-Bench is measuring a mixture of abilities:
context reasoning
+
prior override
+
long-context processing
+
instruction following
Rather than purely testing context learning.
This is an unavoidable limitation of any benchmark built on natural language.
What This Means for AI Agents
Despite these limitations, the paper highlights something important:
AI agents often rely on context engineering.
Instead of fine-tuning models for every task, we:
provide domain knowledge in context
This allows instant specialization without retraining the model.
But if models struggle to apply context correctly, agent systems must be designed carefully.
At Otto, we treat the model as a bounded reasoning component, not an autonomous planner.
How Otto Avoids These Weaknesses
Based on lessons from both research and production systems, Otto follows several design principles.
1. Minimize Inductive Reasoning
Models perform worst when asked to discover patterns or laws from raw data.
Instead we derive structured preference features upstream, something like:
seat_preference = aisle
nonstop_priority = high
red_eye_tolerance = low
The model then reasons over explicit inputs.
2. Control Context Length
Instead of a single giant prompt, Otto uses:
layered retrieval
role-specific context
state compression
reflection based flow
Each model call receives only the context needed for the current task.
3. Break Multi-Turn Dependency Chains
Otto externalizes state:
model output → validated → stored as structured state
Future steps read the validated state rather than relying on conversation history.
4. Separate Policy Extraction From Decision Generation
Otto separates:
Step 1: Extract travel context
Step 2: Validate constraints
Step 3: Generate options
Step 4: Reflect on options
Step 5: Explain recommendation
Each step narrows the reasoning scope.
5. Prefer Structured Rules Over Open Judgment
Example:
IF flight_duration > 5h
AND user didn't permit red-eye flights
THEN expand flight search to include the prior dayStructured reasoning reduces ambiguity.
6. Always Reflect and Verify Outputs
Otto therefore uses verification loops:
proposal model → policy checker → constraint validator → final answer
The system always reflects the model output and adjusts on the feedback.
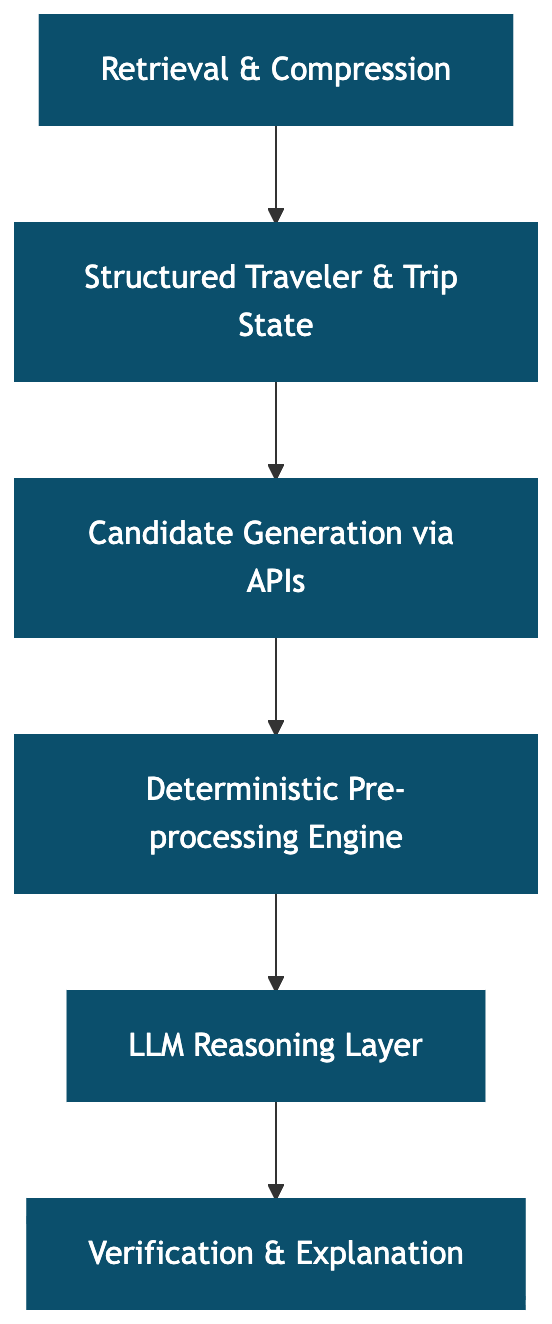
7. Treat the LLM as a Reasoning Layer, Not the Whole System
The architecture roughly looks like:
Final Thoughts
CL-Bench highlights an uncomfortable truth to us:
Frontier foundational models are still weak at reliably learning and applying knowledge from complex context.
But the takeaway is not that agent systems are doomed unless it does post training. Instead, I think it helps clarify how we should build such a system.
Successful AI agents must:
- Reduce inductive reasoning
- Control context size
- Structure decision spaces
- Verify and reflect outputs
When designed this way, the system does not rely on the foundational model being perfect, and improves its accuracy as the models get stronger.
That being said, what traits of the model impact the agentic model the most, and how to leverage existing benchmarks to help decide could be found in my previous post.
Let me know what you think. And feel free to contact me on Linkedin or other social media. Happy to chat, debate or connect.